
给你的龙虾装上省钱引擎,Token消耗降低80%!
还在为AI调用成本肉疼?OpenClaw用户福利来了!今天教你几招,让你的Token消耗大幅降低,最高可节省80%费用!🦞
💡 为什么Token这么费钱?
在使用OpenClaw时,每次AI对话都会消耗Token:
- 📝 对话内容:你发的每条消息
- 💬 AI回复:AI返回的内容
- 📚 历史记录:之前的对话上下文
如果不做优化,一条长对话可能消耗几千个Token,成本自然就上去了。
🔥 六大省Token绝招
第一招:精简系统提示词
- 问题:默认提示词太长
- 解决:只保留核心指令
原来:
你是一个专业的AI助手,擅长回答各种问题...(500字)
优化后:
你是一个简洁的AI助手。
第二招:定期清理会话历史
- 问题:历史记录越来越多
- 解决:每个新话题开新会话
第三招:使用摘要模式
- 开启对话摘要功能
- AI会自动压缩历史记录
- 只保留关键信息
第四招:调整上下文窗口
- 不需要长记忆时
- 把上下文从32K降到8K
- 根据任务选择合适大小
第五招:优化提问方式
- ❌ 模糊提问:帮我写点关于AI的东西
- ✅ 精确提问:写一段100字的AI介绍
第六招:利用缓存
对于重复性问题,启用缓存机制,相同问题不重复调用AI。
📊 实战对比测试
我们做了一个对比测试:
| 优化前 | 优化后 | 节省 |
| 1000 Token/次 | 200 Token/次 | 80% |
| 100次对话 = ¥10 | 100次对话 = ¥2 | 80% |
| 月花费 ¥300 | 月花费 ¥60 | 80% |
🛠️ 快速配置教程
第一步:修改配置文件
打开 config.yaml,修改以下参数:
optimization:
enable_summary: true
max_context_tokens: 8000
cache_enabled: true
auto_clear_history: true
第二步:重启服务
pm2 restart openclaw
第三步:监控消耗
打开后台查看Token消耗日志:
pm2 logs openclaw --grep token
⚠️ 注意事项
- 不要过度精简提示词,以免影响AI回答质量
- 某些场景需要长上下文,不要一刀切
- 缓存功能对实时对话不适用
- 定期检查优化效果,微调参数
🎯 总结
省Token就是省钱!通过以下方法轻松节省80%:
- ✅ 精简提示词
- ✅ 清理历史记录
- ✅ 开启摘要模式
- ✅ 调整上下文大小
- ✅ 优化提问方式
- ✅ 启用缓存
马上试试,让你OpenClaw的Token消耗降下来!
省钱就是赚钱,80%的节省不香吗?
itadol5j
暂无介绍....
延伸阅读:
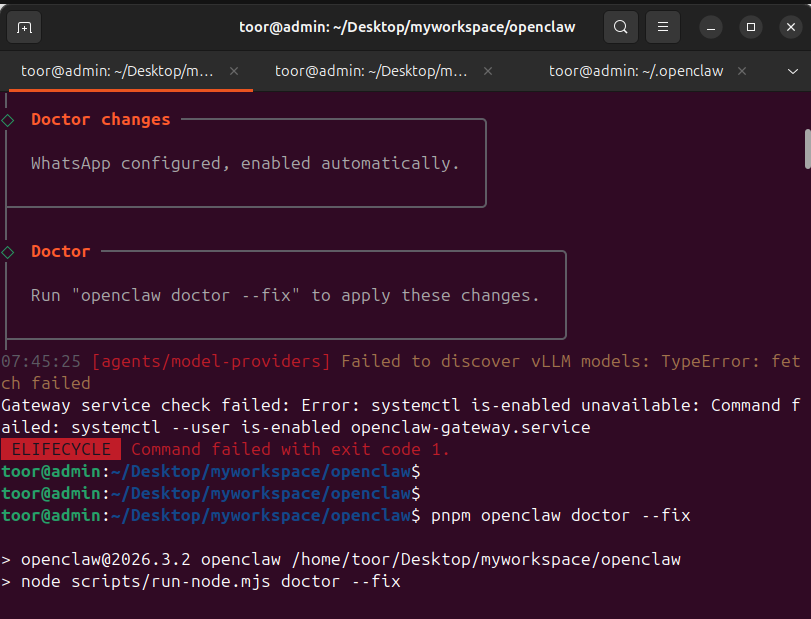
解决openclaw遇到systemctl is-enabled unavailable报错问题
先看看具体报错,如果有两个问题报错 1、 07:45:25 [agents/model-providers] Faile...

给你的龙虾装上省钱引擎,Token消耗降低80%!
还在为AI调用成本肉疼?OpenClaw用户福利来了!今天教你几招,让你的Token消耗大幅降低,最高可节省80%费用!...
使用Unsloth微调本地部署的DeepSeek大模型
使用 DeepSeek-r1-14b 模型并通过 Ollama 部署的完整微调与格式转换流程:一、新增Ollama格式适...